
:quality(80)/p7i.vogel.de/wcms/2c/89/2c8984e0cb11226ac1d4bcfb129daf1c/0132015868v1.jpeg "Nur in einer souveränen Cloud-Umgebung ist KI-Einsatz nicht mit Risiken eines Kontrollverlusts verbunden. (Bild: IONOS)")
:quality(80)/p7i.vogel.de/wcms/c5/45/c54568adfee2a4c6ed992a94abebdb5e/0126992413v1.jpeg "Die souveräne Cloud ermöglicht es, sensible Daten rechtskonform und unter größerer Kontrolle des Kunden zu speichern und zu verarbeiten. (Bild: © Catsby_Art – stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/13/3f/133f5ccfbd6ce74a4f52ca35ea85669f/0127552212v1.jpeg "Alle Gewinner der IT-Awards 2025 unserer Insider-Portale: ausgezeichnet mit Platin, Gold und Silber in jeweils sechs Kategorien – gewählt von unseren Leserinnen und Lesern. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/3b/b8/3bb80b6a0c2e58c6adbe7b40df86aa12/0130692502v2.jpeg "In einer sich wandelnden Landschaft, in der technische Innovationen und menschliche Fähigkeiten Hand in Hand gehen, können Kreativität, soziale Kompetenzen und komplexe Problemlösungen der Schlüssel zu „zukunftssicheren“ Berufen sein. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/38/e8387251b85fc72e0f56d2fa1915043d/0129328744v2.jpeg "Law as Code bezeichnet die digitaltaugliche Bereitstellung des Rechts als ausführbarer Code und ermöglicht so die systematische Umsetzung von Gesetzen in maschinenlesbare Form. (Bild: © InfiniteFlow - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/95/d6/95d6c599b3ff7ee542b413a6bf68af69/0129076535v2.jpeg "Der Begriff Supercloud beschreibt im Wesentlichen die nächste Evolutionsstufe des Cloud Computings und der Multicloud. (Bild: © Khela - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/0d/7a/0d7af67e9a775828b30dc964dbc6e9cd/0132096461v1.jpeg "Im Rahmen des Projekts ECO:DIGIT forschten und entwickelten die teilnehmenden Unternehmen drei Jahre lang offene Werkzeuge für messbare Nachhaltigkeit. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0f/91/0f911ac5df77270faa72b14d3a767dd6/0131961726v1.jpeg "Auf dem Nextcloud Summit 2026 in München feierte Frank Karlitschek, CEO und einer der Gründer von Nextcloud, den zehnten Geburtstag des Open-Source-Unternehmens. Für ihn hat sich Nextcloud zur weltweit führenden Plattform für datenschutzorientierte Zusammenarbeit entwickelt. (Bild: Nextcloud)")
:quality(80)/p7i.vogel.de/wcms/6b/26/6b26926687f1ce00c17a845ef08c41de/0131999273v1.jpeg "Google limitiert die Nutzungsdauer von Gemini über ein rechenbasiertes Kontingent. (Bild: Joos - Google)")
:quality(80)/p7i.vogel.de/wcms/81/90/819070244a9932ac30b92b6b087863de/0131999280v1.jpeg "Der digitale Produktpass begleitet Produkte von der Herstellung bis zum Recycling und legt damit das Fundament für eine echte Kreislaufwirtschaft. (Bild: © Day Of Victory Stu. - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/9d/1a/9d1a884289b071d8d9544cfeb96bd4b0/0132139021v1.jpeg "Den Überblick in der Cloud zu behalten, fällt schwer, wenn IT-Strukturen über Jahre unkontrolliert wuchern. Vereinfachte IT-Strukturen schaffen den nötigen Überblick und senken zugleich die Kosten. (Bild: © Kevin Carden - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4a/5d/4a5d2214d0bae0476500f1975fdfdf2b/0132137617v1.jpeg "Vom Grafikchip zur Spezial-Hardware: Weil GPUs für KI zwar taugen, die Kosten aber „ins Unermessliche“ steigen, setzt Google auf die selbst entwickelte Tensor Processing Unit. (Bild: © Edelweiss - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/07/f9/07f927b43e0f37acfbc4c74e084ab733/0132091115v2.jpeg "Softengine setzt beim Relaunch auf eine modulare ERP-Plattform mit zehn integrierten Lösungen. Diese ermöglicht eine durchgängige Datenbasis, prozessübergreifende Integration und individuelle Anpassung an spezifische Unternehmensanforderungen. (Bild: Softengine)")
:quality(80)/p7i.vogel.de/wcms/05/dc/05dcae1b1f477e809c585b1c5ec0c81e/0132061624v2.jpeg "Wie die byzantinischen Grenzwächter, die auch unter dem Begriff Akrites bekannt waren, soll die gleichnamige Initiative der Linux Foundation kritische Open Source Software und Infrastruktur vor modernen Cyberbedrohungen verteidigen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/82/6f/826f3aea5f67d361ef83f86128ad7213/0131455263v1.jpeg "Modernisierung über Containarisierung und Microservices bietet klare Vorteile. Ungeplant angegangen werden die Nachteile der Monolith-Ära aber gerade weiter verstärkt. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/7b/17/7b177bd72ce296df524e89379c6ac773/0132130322v1.jpeg "Durch raue See in sichere Gewässer: Die Einladung OVHclouds zum Partner Network Summit 2026 auf ein Rheinschiff ist programmatisch. (Bild: Vogel IT-Medien / ewg)")
:quality(80)/p7i.vogel.de/wcms/c3/64/c364066127b64801644390dfccd9623c/0132135985v1.jpeg "Erst anschnallen, dann losfahren: Beim EU AI Act zahlt sich Vorsorge aus. Wer frühzeitig Schutzmaßnahmen etabliert, vermeidet Bußgelder und Reputationsschäden. (Bild: © Olga Ко - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/bf/db/bfdb5824185ff0cc05f43bdbaa69cdb2/0132070340v1.jpeg "Wo sind meine Agenten, womit verbinden sie sich, was dürfen sie tun? Oktas prämierte Lösung „Blueprint for the Secure Agentic Enterprise“ beantwortet diese zentralen Sicherheitsfragen des KI-Einsatzes. (Bild: © Alexander Limbach - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/20/ef/20ef6688330cf6382559149124835ad7/0132041127v2.jpeg "Die Absicherung von SAP-Landschaften gehört zu den zentralen Herausforderungen für IT- und Security-Teams. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/32/22/3222e1f6ce21b6ea24393b4a45bb7ac3/0131969938v1.jpeg "Mit jeder neuen SaaS-Anwendung wächst die Sicherheitslücke: Blinde Flecken führen aber zu Defiziten bei der Datensicherung und bringen mittelständische Unternehmen in größte Gefahr. (Bild: © Rawf8 - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/81/d9/81d9860ff13b0e1669a0bb8d62627ffd/0129330642v1.jpeg "MediaFire kombiniert Upload-Funktionen mit einer dateimanagerähnlichen Oberfläche. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/16/34/16342b5e3dffc397e3b7e9c8cd2ce232/0130625872v1.jpeg "Für praktisch jeden Speicherzweck findet der geneigte Kunde auch passende europäische Angebote. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0e/19/0e19eb5a1ab074734c0597eacdbf030c/0131327372v1.jpeg "Vier europäische Tech-Unternehmen stellten in Berlin das erste vollständig souveräne Notfallwiederherstellungspaket Europas vor, dass die Geschäftskontinuität unabhängig von ausländischen Cloud-Anbietern sicherstellt. (Bild: Cubbit)")
:quality(80)/p7i.vogel.de/wcms/f8/d2/f8d2345e36c633b3b245ce0a345bf5ce/0132089387v2.jpeg "Mehr als jedes zweite Unternehmen gab in der TÜV Weiterbildungsstudie 2026 Qualifizierungsbedarf bei digitalen Kompetenzen an. (Bild: TÜV Weiterbildungsstudie 2026)")
:quality(80)/p7i.vogel.de/wcms/44/bc/44bc26b36c843112c2fa434a7d1c60a8/0132069238v1.jpeg "Cloud- und KI-Projekte sollten nicht einem diffusen Wunsch nach Agilität folgen, sondern mit messbaren Zielen anhand von Zahlen und Prozessen strategisch angegangen werden – der Erfolg lässt dann nicht auf sich warten. (Bild: © Dilok - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/76/b3/76b326ab4ed7137863ef338062d9c02e/0132139031v1.jpeg "Das Gemma 4 12B Modell ist multimodal (Text, Bild, Audio) konzipiert und kann auf Standard-Laptops mit 16 GB RAM ausgeführt werden. Das 12B-Modell erzielt eine Leistung, die nah an das größere 26B-Modell heranreicht. (Bild: Joos - Google)")
Wo sind all die Dienste hin? Worauf es bei Cloud-Ausfällen ankommt
Flexibel, skalierbar und kostengünstig: Die Dienste der Cloud-Giganten wie Amazon, Google oder Microsoft haben hunderttauende Kunden in Europa überzeugt. Aber was passiert, wenn deren Cloud-Infrastruktur ausfällt?
Anbieter zum Thema
Die Cloud ist in den meisten deutschen Firmen Alltag. So nutzen 75 Prozent der deutschen Unternehmen einen Provider, 67 Prozent haben bereits zwei und 42 Prozent sogar drei Cloud-Dienstleister unter Vertrag. Dies zeigt die Truth in Cloud Studie von Veritas. Die Dienstleister haben zurecht einen ausgezeichneten Ruf, was die Verfügbarkeit ihrer Dienste betrifft. In den vergangenen Jahren sind ihre Dienste nur sehr selten und dann nur kurz komplett ausgefallen. Trotzdem bleibt ein Restrisiko, das umso stärker ins Gewicht fällt, je wichtiger die Dienste der Unternehmen sind, die auf der Cloud laufen. Es ist deshalb wichtig, dass IT-Verantwortliche wissen und verstehen, wo Gefahren lauern und wo die Verantwortlichkeiten liegen.
Die Provider selbst handeln nach einem Shared Responsibility Modell, bei dem immer ein Teil der Verantwortung beim Kunden liegt. So bleibt der Kunde immer für seine Daten und deren Compliance verantwortlich. Werden Daten korrumpiert oder gehen verloren, liegt die Verantwortung aufseiten der Kunden, diese aus einem eigenen Backup zu rekonstruieren.
:quality(80)/images.vogel.de/vogelonline/bdb/1454100/1454113/original.jpg "(Veritas)")
:quality(80)/images.vogel.de/vogelonline/bdb/1454100/1454114/original.jpg "(Veritas)")
:quality(80)/images.vogel.de/vogelonline/bdb/1454100/1454115/original.jpg "(Veritas)")
Das ist auf Firmenseite noch zu wenig in den Köpfen mancher IT-Leiter verankert, denn weitere Ergebnisse der Veritas Studie zeigen: 83 Prozent der deutschen Firmen, die IaaS nutzen oder dies planen, sehen die Verantwortung für Datensicherung in der Cloud bei den Cloud Service Providern. Und 69 Prozent sind fest überzeugt, dass sie die Verantwortung für Datensicherheit, Datenschutz und Compliance an ihre Cloud Service Provider delegieren können. Wer mit den Daten seinen Teil der Verantwortung in die Cloud schiebt, ist für den Ernstfall schlecht oder gar nicht vorbereitet.
Auch in Fragen der Hochverfügbarkeit ist manchem IT-Leiter nicht klar, was die Cloud Provider abdecken und was ein Unternehmen selbst tun muss. So geben die Public-Cloud-Dienstleister klare und strenge Garantien für ihre Service Level ab, diese beziehen sich aber meistens nur auf die Verfügbarkeit der Infrastruktur in der Cloud. Fällt sie aus, müssen die Provider sie wieder zum Laufen bringen. Doch danach liegt es an Kunden, die darauf laufenden Dienste und Anwendungen selbst wieder in Betrieb zu nehmen. Je komplexer die Anwendungen strukturiert sind und je mehr Daten während des Ausfalls verloren gehen, desto länger wird die Wiederherstellung der kritischen Applikationen dauern. Oft nutzen die IT-Abteilungen für diese Aufgabe isolierte Tools und manuelle Prozesse, ohne Automatismen. Da geht im Ernstfall wertvolle Zeit verloren, die sich dann in teurer Downtime der wichtigen Dienste manifestiert.
Testen im laufenden Betrieb
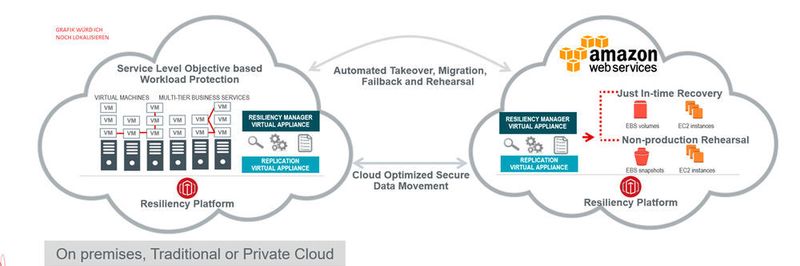
Die Wiederherstellung der Daten und Dienste nach einem Cloud-Ausfall ist dann schwer beherrschbar und wird unkalkulierbar. IT-Leiter können ein klares Zeichen setzen, wenn sie diese wichtigen Prozesse professionalisieren. Für diesen Zweck gibt es Lösungsansätze wie die Business-Continuity-Plattofrm „Resiliency Platform“ von Veritas. Sie helfen dabei, mehrstufige Applikationsarchitekturen und ihre Verfügbarkeit rund um die Uhr zu kontrollieren, den Ausfallprozess zu testen und den Failover-Prozess im Ernstfall mit einem Mausklick automatisch und kontrolliert abzuwickeln.
Solche Konzepte müssen sich eng an die Infrastruktur der führenden Cloud-Anbieter ankoppeln, um nahtlos von einer Cloud-Infrastruktur auf eine andere oder auf ein lokales Rechenzentrum des Kunden umschalten zu können. Dafür nutzen sie deren Protokolle, Dienste und Data Mover und sind von den wichtigen Cloud Providern entsprechend zertifiziert. Sie sind daher auch in der Lage, die Struktur der Applikationen sowohl on premises als auch in der Cloud automatisch und mit geringer Fehlerquote per Autodiscovery zu erfassen, zu verstehen und die zu sichernden Applikations-Elemente so zu identifizieren. Die IT-Abteilung wird entlastet und es ist weniger wahrscheinlich, dass ein essenzieller Teil einer mehrstufigen Applikation übersehen wird.
Die Ergebnisse der Autodiscovery laufen in einer zentralen grafischen Oberfläche und einem Dashbard zusammen. Dort kann der IT-Verantwortliche, die Ergebnisse des gesamten Disaster-Recovery-Prozesses überblicken und per Drag & Drop modellieren. Im nächsten Schritt kann er einen großen Vorteil einer solchen übergreifenden Instanz ausspielen – das Testen des gesamten Vorgangs, ohne den Betrieb zu stören.
Per Mausklick lassen sich belastbare Werte in der Praxis ermitteln, wie lange der gesamte Umschaltprozess dauert, wie viele Produktiv-Daten verloren gehen. Der Ernstfall wird auf einmal berechenbar und kalkulierbar. Den zweiten großen Vorteil spielen solche Business-Continuity-Plattformen dann im Ernstfall aus – ihren Automatismus, der in der Krisensituation den komplexen Failover-Prozess automatisch abwickelt, und zwar nach den vorher im Test gemessenen Kriterien für die Dauer und die Menge der Daten, die während der Umschaltzeit verloren gehen könnten. IT-Leiter wissen nun, wie lange es dauert, wichtige Geschäftsanwendungen wiederherzustellen. Denn sie können mit Werten, die unter realen Bedingungen ermittelt wurden, den Ernstfall beschreiben.
Wissen was zu tun ist
Es ist gut , wenn IT-Leiter die Folgen eines Cloud-Ausfalls genau verstehen und sich darüber im Klaren sind, dass die Wiederherstellung nach dem Ausfall nur gemeinsam mit dem Cloud Service Provider zu stemmen ist. Richten Unternehmen für ihre Anwendungen bereits im Vorfeld entsprechende Ausfallmechanismen für die Multi-Cloud ein, haben sie im Ernstfall nicht nur die volle Verantwortung, sondern auch die volle Kontrolle über die Wiederherstellung ihrer kritischen Services. So reduziert der IT-Leiter Ausfallzeiten, einen Vertrauensverlust auf Kundenseite und damit finanzielle Schäden.
Der Autor: Mathias Wenig, Senior Manager TS und Digital Transformation Specialist bei Veritas.
(ID:45494931)
:quality(80)/p7i.vogel.de/wcms/10/7e/107e2a602907f5f8c0706628e52c3a9c/0125332406v1.jpeg "Für die Sicherung der Daten, die in Public-Cloud-Lösungen wie MS365 gespeichert werden, hat der Kunde selbst zu sorgen. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/47/c3/47c38f4359d38b21aa65391358de5fca/0128106074v1.jpeg "Daten sind wertvoll und auch in SaaS-Zeiten muss gesichert werden. (Bild: Midjourney / KI-generiert)")