
:quality(80)/p7i.vogel.de/wcms/2c/89/2c8984e0cb11226ac1d4bcfb129daf1c/0132015868v1.jpeg "Nur in einer souveränen Cloud-Umgebung ist KI-Einsatz nicht mit Risiken eines Kontrollverlusts verbunden. (Bild: IONOS)")
:quality(80)/p7i.vogel.de/wcms/c5/45/c54568adfee2a4c6ed992a94abebdb5e/0126992413v1.jpeg "Die souveräne Cloud ermöglicht es, sensible Daten rechtskonform und unter größerer Kontrolle des Kunden zu speichern und zu verarbeiten. (Bild: © Catsby_Art – stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/13/3f/133f5ccfbd6ce74a4f52ca35ea85669f/0127552212v1.jpeg "Alle Gewinner der IT-Awards 2025 unserer Insider-Portale: ausgezeichnet mit Platin, Gold und Silber in jeweils sechs Kategorien – gewählt von unseren Leserinnen und Lesern. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/3b/b8/3bb80b6a0c2e58c6adbe7b40df86aa12/0130692502v2.jpeg "In einer sich wandelnden Landschaft, in der technische Innovationen und menschliche Fähigkeiten Hand in Hand gehen, können Kreativität, soziale Kompetenzen und komplexe Problemlösungen der Schlüssel zu „zukunftssicheren“ Berufen sein. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/38/e8387251b85fc72e0f56d2fa1915043d/0129328744v2.jpeg "Law as Code bezeichnet die digitaltaugliche Bereitstellung des Rechts als ausführbarer Code und ermöglicht so die systematische Umsetzung von Gesetzen in maschinenlesbare Form. (Bild: © InfiniteFlow - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/95/d6/95d6c599b3ff7ee542b413a6bf68af69/0129076535v2.jpeg "Der Begriff Supercloud beschreibt im Wesentlichen die nächste Evolutionsstufe des Cloud Computings und der Multicloud. (Bild: © Khela - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/6b/26/6b26926687f1ce00c17a845ef08c41de/0131999273v1.jpeg "Google limitiert die Nutzungsdauer von Gemini über ein rechenbasiertes Kontingent. (Bild: Joos - Google)")
:quality(80)/p7i.vogel.de/wcms/81/90/819070244a9932ac30b92b6b087863de/0131999280v1.jpeg "Der digitale Produktpass begleitet Produkte von der Herstellung bis zum Recycling und legt damit das Fundament für eine echte Kreislaufwirtschaft. (Bild: © Day Of Victory Stu. - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/54/45/544507cda06b7f6760e037221213fed3/0131953381v2.jpeg "Red Hat stärkt die digitale Unabhängigkeit von Unternehmen mit neuen Funktionen für souveräne und private Clouds. (Bild: Canva / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/67/81/67819209b1ae42da05118af95393dfaf/0131298906v1.jpeg "Die Kosten für eine private Cloud mittels VMware-Tools, wachsen seit der Broadcom-Übernahme für viele in den Himmel. Vor allem für Mittelständler ist das ein Problem. (Bild: © Maksym - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/20/ef/20ef6688330cf6382559149124835ad7/0132041127v2.jpeg "Die Absicherung von SAP-Landschaften gehört zu den zentralen Herausforderungen für IT- und Security-Teams. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ac/f1/acf1f5a5ecaf770e0bd31a841af30483/0131955650v2.jpeg "Die KI-basierte Cortex-Plattform von Palo Alto Networks wird mit der Deutschen Telekom für regulierte Branchen ausgebaut. Sovereign Cortex with T Security bietet Cloud-Services mit erweiterten Kontrollen über Datenzugriff und Verschlüsselung. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/1e/44/1e44d1268860f36be07511421c073a9d/0130913773v1.jpeg "Europäische Gegenwehr: Toplink und Nextcloud schmieden eine Office-Plattform mit eigenem Telefonnetz im Rücken. (Bild: Toplink GmbH)")
:quality(80)/p7i.vogel.de/wcms/6a/0c/6a0c064c1067cc3e1c30c12730d9cf5c/0131935848v2.jpeg "Da KI-Agenten zunehmend autonom über Tools, APIs, Cloud und Edge agieren, müssen Sicherheitsteams in Echtzeit wissen, worauf sie zugreifen, was sie tun und wie sich das steuern lässt. (Bild: Canva / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/9c/3b/9c3bf5e62dbf4de65c2cd97331e7b637/0132040915v1.jpeg "Wer KI unkontrolliert skaliert, häuft technische Schulden an – wer sie wie ein diszipliniertes Produktionssystem führt, gewinnt Zuverlässigkeit, Kostenkontrolle und Geschwindigkeit. (Bild: © ZinetroN - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/2f/e5/2fe53f05af74d4db7644f322c69f66c2/0132094303v1.jpeg "Meta will überzählige KI-Ressourcen als Service anbieten. Die Gerüchte dazu verliehen der Aktie einen kräftigen Schub. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/26/e826122f9f8106713a1ec0d107e67709/0132084622v1.jpeg "KI-Rechenzentren sollen der neue Jobmotor im Rheinischen Revier werden. Dort wo früher Kohle dominierte, ist es nun die Rechenleistung. Microsoft will dort weiter investieren. (Bild: © Jason - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/32/22/3222e1f6ce21b6ea24393b4a45bb7ac3/0131969938v1.jpeg "Mit jeder neuen SaaS-Anwendung wächst die Sicherheitslücke: Blinde Flecken führen aber zu Defiziten bei der Datensicherung und bringen mittelständische Unternehmen in größte Gefahr. (Bild: © Rawf8 - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/23/e0/23e07392b49c901abc9d5923c1980e95/0131958408v1.jpeg "Wenn Single Points of Failure zur Realität werden und die Cloud am Ende komplett ausfällt, können Nutzende nur verzweifeln. (Bild: © deagreez - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/81/d9/81d9860ff13b0e1669a0bb8d62627ffd/0129330642v1.jpeg "MediaFire kombiniert Upload-Funktionen mit einer dateimanagerähnlichen Oberfläche. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/16/34/16342b5e3dffc397e3b7e9c8cd2ce232/0130625872v1.jpeg "Für praktisch jeden Speicherzweck findet der geneigte Kunde auch passende europäische Angebote. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0e/19/0e19eb5a1ab074734c0597eacdbf030c/0131327372v1.jpeg "Vier europäische Tech-Unternehmen stellten in Berlin das erste vollständig souveräne Notfallwiederherstellungspaket Europas vor, dass die Geschäftskontinuität unabhängig von ausländischen Cloud-Anbietern sicherstellt. (Bild: Cubbit)")
:quality(80)/p7i.vogel.de/wcms/16/0a/160ad8abbe2e7d54fd3755c97bf8aed3/0131570547v1.jpeg "Ein Co-Brain ist die digitale, KI-basierte Version einer realen Person in einem Unternehmen und kann ihrer Rolle entsprechend zu bestimmten Bereichen Fragen beantworten, Ratschläge geben oder Einsichten vermitteln. (Bild: © Tryfonov - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1a/0b/1a0b469e4134a3efaabaad8fa7f4df34/0132049313v1.jpeg "Die Sonderpublikation „Digitale Souveränität“ steht registrierten Lesern kostenfrei zum Download bereit. (Bild: Vogel IT-Medien)")
Scality Open Source Software baut auf Erfolg des S3 Server Multi-Cloud Data Controller mit S3 API
Scality präsentiert einen kostenlos nutzbaren Multi-Cloud Data Controller. Zu AWS S3 kompatible Anwendungen nutzen mit der Zenko genannten Open-Source-Software ohne weitere Anpassung On-Premise-Server oder Microsoft Azure Blob Storage.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/6c/686cc778b54e4/flexera-no-tagline-rgb-full-color.png "flexera-no-tagline-rgb-full-color (Flexera Software GmbH)")
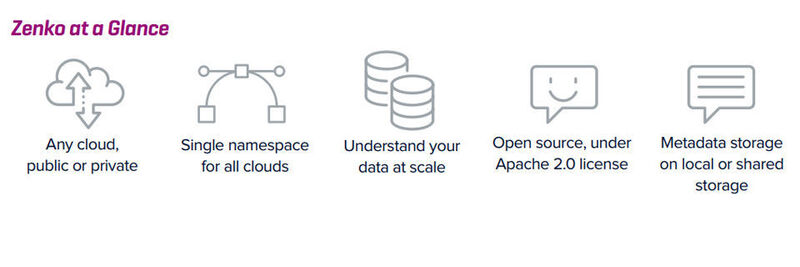
Scality – ein Anbieter für softwaredefinierte Speicher – beschreibt Zenko als Multi-Cloud Controller. Die Open-Source-Lösung soll eine einheitliche Schnittstelle bereitstellen, mit der Anwendungen auf die verschiedensten Cloudspeicher zugreifen können. Dabei nutze die auf dem Erfolg des Scality S3 Server aufbauende Lösung eine Implementierung des AWS Simple Cloud Storage Service (S3).
Somit könne jede S3-kompatible Anwendung beispielsweise auch auf On-Premise-Systeme oder öffentliche Dienste wie Microsoft Azure Blob Storage zugreifen. Über Zenko geschriebene Daten werden direkt im nativen Format des Zielspeichers gespeichert und können direkt wieder ausgelesen werden.
Der Anbieter beschreibt den Leistungsumfang wie folgt:
- S3 API – Scality Zenko bietet eine einzige einheitliche Schnittstelle mit dem Amazon S3 API und unterstützt Multi-Cloud-Backend-Datenspeicherung sowohl On-Premise als auch in öffentlichen Clouddiensten. Zenko ist ab sofort für Microsoft Azure Blob Storage, Amazon S3, Scality RING und Docker erhältlich und soll in Kürze für andere Cloud-Plattformen verfügbar sein.
- Natives Format – Daten, die über Zenko geschrieben wurden, werden im nativen Format des Zielspeichers gespeichert und können direkt gelesen werden, ohne über Zenko gehen zu müssen. Daher könnten Daten, die in Azure Blob Storage oder in Amazon S3 geschrieben sind, die entsprechenden fortgeschrittenen Dienste dieser öffentlichen Clouds nutzen.
Für September kündigt Scality folgende Erweiterungen an:
- Backbeat-Daten-Workflow – Eine richtlinienbasierte Datenmanagement-Engine, die für nahtlose Datenreplikation, Datenmigrationsdienste oder erweiterte Cloud-Workflow-Services wie Cloudanalyse und Inhaltsverteilung eingesetzt wird.
- Clueso-Metadatensuche – Eine „Apache Spark“-basierte Metadatensuche nach erweiterten Informationen zum Verständnis der Daten. Clueso mache es einfach, Daten im Petabyte-Maßstab auf allen Clouds zu interpretieren und problemlos zu manipulieren, um hochwertige Informationen von Datenrauschen zu trennen. Dabei können Daten anhand von Schlüsselattributen zu unterteilt werden.
Zenko wird unter einer „Apache 2.0“-Lizenz veröffentlicht. Entwickler sollen die Lösung in diesem Rahmen nutzen und erweitern. Weitere Details gibt es auf der Website www.zenko.io.
:quality(80)/images.vogel.de/vogelonline/bdb/1244400/1244460/original.jpg "Multi-Cloud-Szenarien können Vorteile, aber auch Einschränkungen bieten, und sollten daher individuell auf das jeweilige Geschäftsbedürfnis ausgelegt sein. (© BillionPhotos.com/Fotolia)")
Cloud Data Brokers verringern die Komplexität
Der Aufstieg der Multi-Clouds und Data Controller
(ID:44794351)
:quality(80)/p7i.vogel.de/wcms/8e/48/8e48dae6f6a817f9d6ef8872bd4733e6/0125882314v1.jpeg "Mir der Open-Source-Lösung Zenko von Scality lassen sich komplexe Speicherarchitekturen über eine einheitliche API hinweg abstrahieren. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/37/3c/373c6ac79968234524e119bf1dc3cf82/0129879786v1.jpeg "Das Open-Source-Projekt OpenCloud bietet eine sichere und private Möglichkeit, Dateien zu speichern, darauf zuzugreifen und sie zu teilen. (Bild: OpenCloud)")