
:quality(80)/p7i.vogel.de/wcms/c5/45/c54568adfee2a4c6ed992a94abebdb5e/0126992413v1.jpeg "Die souveräne Cloud ermöglicht es, sensible Daten rechtskonform und unter größerer Kontrolle des Kunden zu speichern und zu verarbeiten. (Bild: © Catsby_Art – stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/13/3f/133f5ccfbd6ce74a4f52ca35ea85669f/0127552212v1.jpeg "Alle Gewinner der IT-Awards 2025 unserer Insider-Portale: ausgezeichnet mit Platin, Gold und Silber in jeweils sechs Kategorien – gewählt von unseren Leserinnen und Lesern. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/3b/b8/3bb80b6a0c2e58c6adbe7b40df86aa12/0130692502v2.jpeg "In einer sich wandelnden Landschaft, in der technische Innovationen und menschliche Fähigkeiten Hand in Hand gehen, können Kreativität, soziale Kompetenzen und komplexe Problemlösungen der Schlüssel zu „zukunftssicheren“ Berufen sein. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/38/e8387251b85fc72e0f56d2fa1915043d/0129328744v2.jpeg "Law as Code bezeichnet die digitaltaugliche Bereitstellung des Rechts als ausführbarer Code und ermöglicht so die systematische Umsetzung von Gesetzen in maschinenlesbare Form. (Bild: © InfiniteFlow - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/95/d6/95d6c599b3ff7ee542b413a6bf68af69/0129076535v2.jpeg "Der Begriff Supercloud beschreibt im Wesentlichen die nächste Evolutionsstufe des Cloud Computings und der Multicloud. (Bild: © Khela - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/ff/22/ff229cfde46e8cdbd2def659dc1a1366/0131266993v1.jpeg "Die Gemini-App erstellt jetzt ohne App-Wechsel direkt aus dem Prompt fertige Dateien in Word, Excel, PDF und Google-Workspace-Formaten. (Bild: Joos - Google)")
:quality(80)/p7i.vogel.de/wcms/ae/f1/aef1db70325fb40dde674f774f583eb5/0130594750v1.jpeg "CloudM ist eine Plattform für Cloud-Datenmanagement mit Fokus auf Google Workspace und Microsoft 365, die Datenmigration, Nutzerverwaltung und Geschäftskontinuität abdeckt. (Bild: © Starmarpro - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/3b/ff/3bfffe7201cab3bb7cb2988549db0c39/0131528304v1.jpeg "Die Frontier Suite, die am 9. März 2026 von Microsoft vorgestellt wurde, vereint Produktivität, KI, Sicherheit und Identitätsmanagement auf einer einzigen Plattform. (Bild: frei lizenziert Stocksnap)")
:quality(80)/p7i.vogel.de/wcms/d2/91/d29106faa9c797de960292838ae455ee/0131601665v2.jpeg "Die Produktupdates hat DocuWare auf der DocuWorld in Berlin angekündigt. (Bild: DokuWare)")
:quality(80)/p7i.vogel.de/wcms/12/9f/129f457d9e29121fefef8fc9ae1f4d6c/0131597620v2.jpeg "Unter dem Druck des Managements wiegt die schnelle Veröffentlichung von Software oft mehr als ihre Qualität. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/31/df/31df70dc9aba2df0756027ace9211392/0131107808v2.jpeg "Das Stimmungsbild 2026 der Stiftung Datenschutz zeigt: Fast die Hälfte der Unternehmensführer in Deutschland sieht Datenschutz als strategischen Standortfaktor – und trotzdem stuft ein gutes Drittel den eigenen Handlungsbedarf als hoch ein. (Bild: Canva / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/bd/e5/bde5767a1ab00c441b46d359749dcccc/0131265436v1.jpeg "Europa verfügt sowohl über das nötige technische Know-how als auch die erforderlichen regulatorischen Rahmenbedingungen, um ein KI-Modell zu etablieren, das leistungsstark, überprüfbar und frei von aufgezwungenen Abhängigkeiten ist. (Bild: © ImageFlow - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/db/25/db25b42919c7b89e74159db9b83009cb/0131107828v2.jpeg "Die erste Maus:
Der Prototyp des noch heute weit verbreiteten Standard-Eingabegeräts für Computer wurde 1963 von Bill English nach Skizzen von Douglas Engelbart gebaut. (Bild: SRI Computer Mouse / CC BY-SA / Wikimedia Commons)")
:quality(80)/p7i.vogel.de/wcms/78/39/78393d4add08a8ef46e4ac1cbfddadbd/0131124773v1.jpeg "Unternehmen, die ihre Stammdaten entlang der gesamten Wertschöpfungskette sorgfältig pflegen, können aus ihrer Datenbasis signifikante Effizenzgewinne erzielen. (Bild: © Rully J - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/be/fb/befb8db9f26b45c7d428f861f1efb8c0/0131549908v1.jpeg "Deutschland zählt laut einer Studie von Avanade und Accenture zu den weltweit führenden Ländern bei souveränen Cloud-Strategien und Investitionen in Digitale Souveränität. (Bild: ChatGPT / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/01/8f/018fbf10657dc3731cd869bc69ba5570/0130772709v2.jpeg "Mit der korrekten Konfiguration des Microsoft-365-Tenants steht und fällt der Unternehmensbetrieb. Menschliche Fehler, Insider-Bedrohungen und Tenant-Übernahmen gehören zu den größten Risiken. (Bild: © Santiago - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/67/d2/67d2826999d0ccbbb938fedc53387e33/0131077259v1.jpeg "Streng genommen ist souveräner Cloud-Betrieb Voraussetzung für die Einhaltung des Datenschutzes nach DSGVO, die den Verbleib personenbezogener Daten innerhalb ihres Anwendungsbereichs fordert. (Bild: © CuteBee - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0e/19/0e19eb5a1ab074734c0597eacdbf030c/0131327372v1.jpeg "Vier europäische Tech-Unternehmen stellten in Berlin das erste vollständig souveräne Notfallwiederherstellungspaket Europas vor, dass die Geschäftskontinuität unabhängig von ausländischen Cloud-Anbietern sicherstellt. (Bild: Cubbit)")
:quality(80)/p7i.vogel.de/wcms/2e/04/2e041e93b1d72f6580291bb5f234b5c5/0130963060v1.jpeg "Das Datenverzeichnis bildet den technischen Kern jeder Nextcloud-Installation – Architektur und Storage-Design entscheiden über Performance, Skalierbarkeit und digitale Souveränität. (Bild: © PicDY - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/81/bf/81bf238709bbe95944c3060987a03a87/0130887672v1.jpeg "Von Technik zu Taktik: Kluge Cloud-Entscheidungen sichern über die Effizienz hinaus Souveränität und Sicherheit. (Bild: © Gorodenkoff - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b6/f7/b6f78db91e856c49b8cdb62d1ac26bdc/0130861223v1.jpeg "Seafile speichert Dateien sicher auf dem eigenen Server, synchronisiert sie über alle Geräte und erleichtert das Teilen und die Zusammenarbeit – als Open-Source-Plattform für File Sync & Share. (Bild: Seafile)")
:quality(80)/p7i.vogel.de/wcms/16/c8/16c8ff5b6ee25fe71508977862c68645/0131567078v2.jpeg "Ab Mitte 2027 können niederländische Unternehmen die gemeinsame souveräne Cloud-Lösung von Schwarz Digits und KPN über den TK-Konzern und dessen Partnernetzwerk beziehen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/a4/96/a4960aec18b7dc7f0d33194dafdf44b8/0131065219v1.jpeg "Microsoft integriert GPT Image 2 in seine KI-Plattform Foundry. (Bild: Joos - Microsoft)")
:quality(80)/p7i.vogel.de/wcms/16/f2/16f28feaa8303c945c89d00f4bb729cd/0131061532v1.jpeg "Managed Services 2.5 nutzt die Geschwindigkeit und Skalierbarkeit von KI, wo sie bereits zuverlässig funktioniert, und schalltet für kritische Entscheidungen menschliche Expertise dazwischen. (Bild: © robertchouraqui - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/e3/7a/e37a853307b036842e48949f5a0f3826/0130736761v1.jpeg "Die Branchenriesen positionieren sich strategisch in den Zukunftsmärkten Software und künstliche Intelligenz. (Bild: Midjourney / KI-generiert)")
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
Das Matching
Wenn das Profiling abgeschlossen wurde, kann es daran gehen, das Matching durchzuführen, um doppelte Einträge aus den Datenbanken zu entfernen. Dazu stellt der Data Profiler den Befehl „Remove Duplicats“ zur Verfügung, der automatisch einen Reinigungsjob für die gefundenen doppelten Einträge generiert. Im Test entfernten wir auf diese Weise schnell und einfach sämtliche Doubletten aus unserer Datenbank. Wie in der Einleitung bereits angesprochen, ist es aber sinnvoll, beim Erkennen der Doubletten über die Score-Funktion gewisse Grenzwerte zu setzen und inkonsistente Daten in der Data Stewardship Console manuell zu überprüfen, damit keine wichtigen Einträge verloren gehen.
Über die Matching-Funktion lässt sich auch verhindern, dass überhaupt Doubletten entstehen. So ist es beispielsweise denkbar, einen Task zu erstellen, der eingehende neue Adressdaten mit einer Referenztabelle vergleicht und die neuen Informationen nur dann in die Datenbank einträgt, wenn sie dort noch nicht vorhanden sind. Verschiedene Matching-Algorithmen sorgen in diesem Zusammenhang beispielsweise für das automatische Erkennen von Buchstabendrehern und ähnlichem.
Record Consolidation
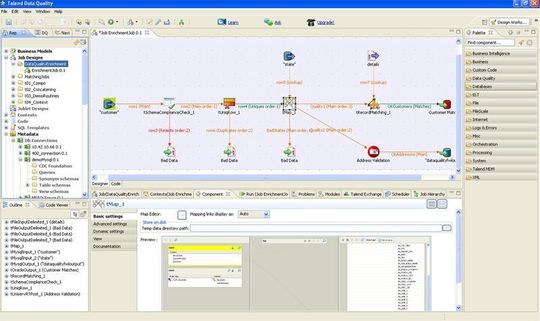
Mit ähnlichen Methoden wie beim Matching lassen sich auch automatisch Daten aus verschiedenen Quellen zusammenführen, um einheitliche und vollständige Datensätze zu erhalten. Zusätzlich stehen auch Aliastabellen zur Fehlerkorrektur zur Verfügung, etwa um das Format einer Bestellnummer zu vereinheitlichen (12-345 statt 12345). Dank dieser Funktionen sind viele Arbeitsschritte automatisierbar und Grenzwerte helfen wiederum dabei, unklare Datensätze auszufiltern und an die Data Stewardship Console zur Weiterverarbeitung zu übergeben.
Im Test verhielten sich die Jobs wie erwartet und lösten die offensichtlichen Unklarheiten automatisch auf, während sie zweifelhaften Fälle der Console überließen. Es ist in der Praxis aber sinnvoll, vor der Arbeit mit echten Daten erst einmal ein paar Probeläufe in einer Testumgebung durchzuführen, um die Grenzwerte optimal festzulegen. Sonst zerstört das System möglicherweise einige Datensätze oder es bleibt zu viel Handarbeit liegen.
Die Data Stewardship Console
Kommt die Datenqualitätslösung bei ihren Analysen zu keinen klaren Ergebnissen, so sollten die zuständigen Mitarbeiter die übrig gebliebenen unklaren Einträge wie bereits angesprochen manuell prüfen, vervollständigen und in die Datenbank zurückschreiben. Um diesen Schritt auf einfache Weise von einem beliebigen Ort aus durchführen zu können, steht die im zweiten Teil der Reihe näher vorgestellte Data Stewardship Console zur Verfügung. In unserem Test hatten wir zu diesem Zeitpunkt bereits mit den eben beschriebenen Methoden diverse Datenanalysen abgeschlossen, bei denen etliche Datensätze angefallen waren, die das System bei unseren Einstellungen nicht von selbst bereinigen konnte.
Folglich loggten wir uns nun mit unserem Webbrowser über die URL
http://{IP-Adresse des Servers}:8080/org.talend.datastewardship/login.jsp
bei der Data Stewardship Console ein. Danach fanden wir uns in einem Verwaltungstool wieder, das am oberen Rand über eine Menüzeile und auf der linken Seite über eine Baumstruktur verfügte. Die Menüzeile umfasste eine Suchfunktion und die Möglichkeit, die Sprache des Interfaces umzustellen (Englisch oder Französisch, Übersetzungen in viele andere Sprachen sind ebenfalls verfügbar, diese erstellt Talend in Zusammenarbeit mit der Community). Die Baumstruktur enthielt die offenen Aufgaben.
weiter mit: Arbeiten mit der Data Stewardship Console und abschließendes Fazit
(ID:2051899)
:quality(80)/p7i.vogel.de/wcms/8d/ab/8dab258e0eb14a71b53298faffd4aaba/0128585584v2.jpeg "Windows Backup for Organizations sichert Einstellungen und Store-Apps cloudbasiert und bietet die Wiederherstellung bereits im OOBE an. Es ersetzt jedoch kein klassisches Backup. (Bild: © Miha Creative - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/2a/67/2a670dcc420afba3d42871595592803a/0126619828v1.jpeg "Schritt für Schritt: So lassen sich BaaS-Backends konfigurieren und per SDK nahtlos in Anwendungen integrieren. (Bild: © hakinmhan - stock.adobe.com)")